Lecture 20
Correlation between numerical variables
Correlation between numerical variables
ABD 3e Chapter 16
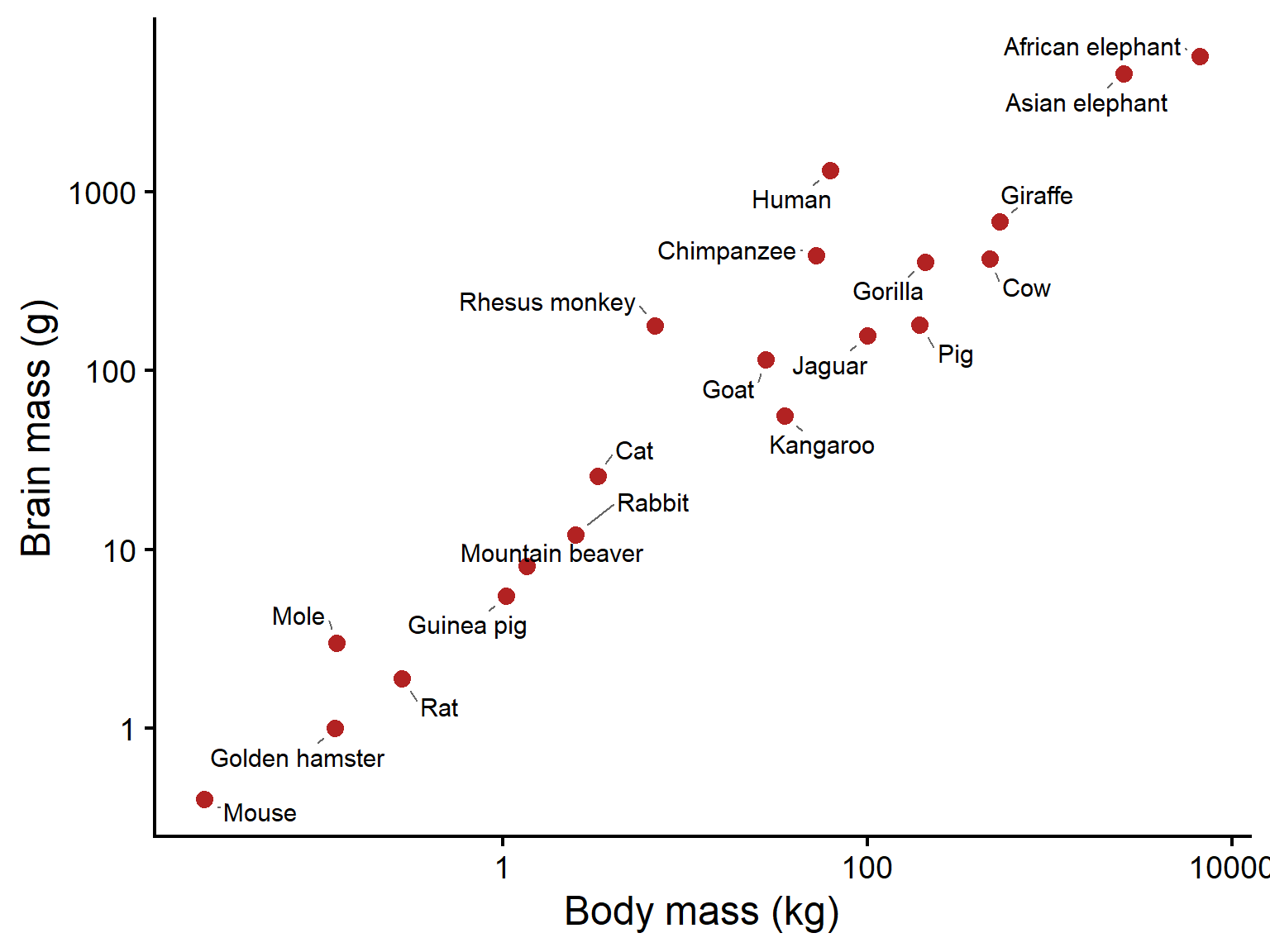
Example: body mass and brain mass in mammals
- Each point represents one mammal species
- Species with larger body mass tend to have larger brain mass
- This is a positive correlation: \(X \uparrow,\ Y \uparrow\)
- The relationship is strong, but not perfect
- Some species have larger or smaller brains than expected for their body size
Correlation does not imply causation
- A correlation means two variables are associated, not that one causes the other
- X may affect Y, Y may affect X, or both may be influenced by a third variable
- Coincidental correlations can also occur by chance
- Correlation alone cannot establish cause-and-effect relationships

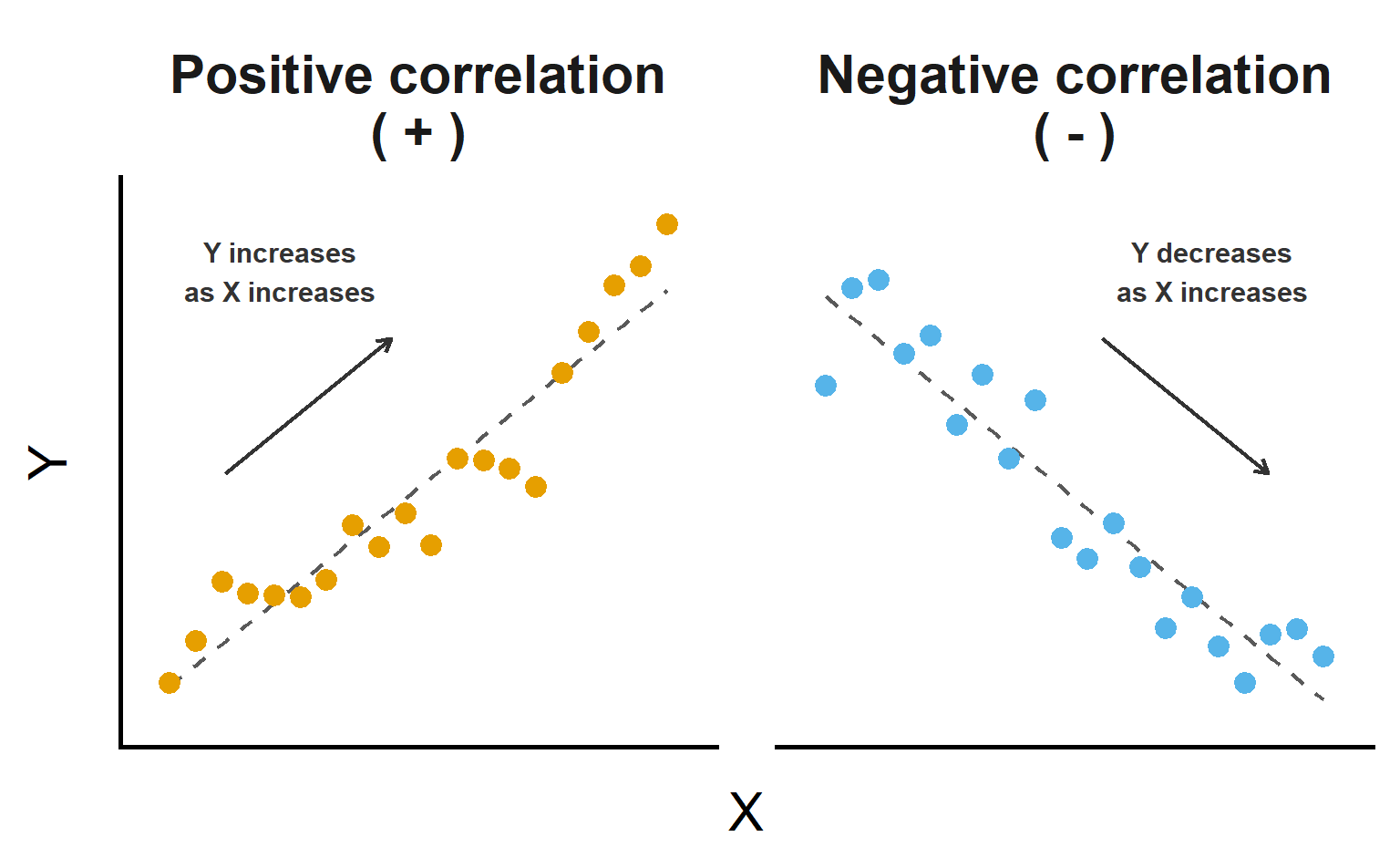
Direction of correlation
- Positive correlation: as one variable increases, the other tends to increase
- Negative correlation: as one variable increases, the other tends to decrease
- The sign of the correlation describes the direction of association
- Direction does not tell us how strong the relationship is
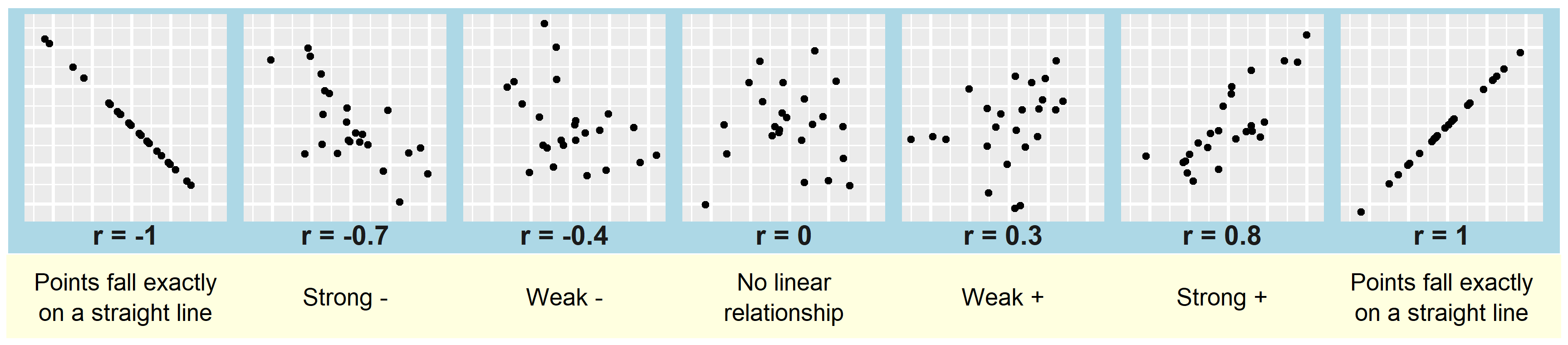
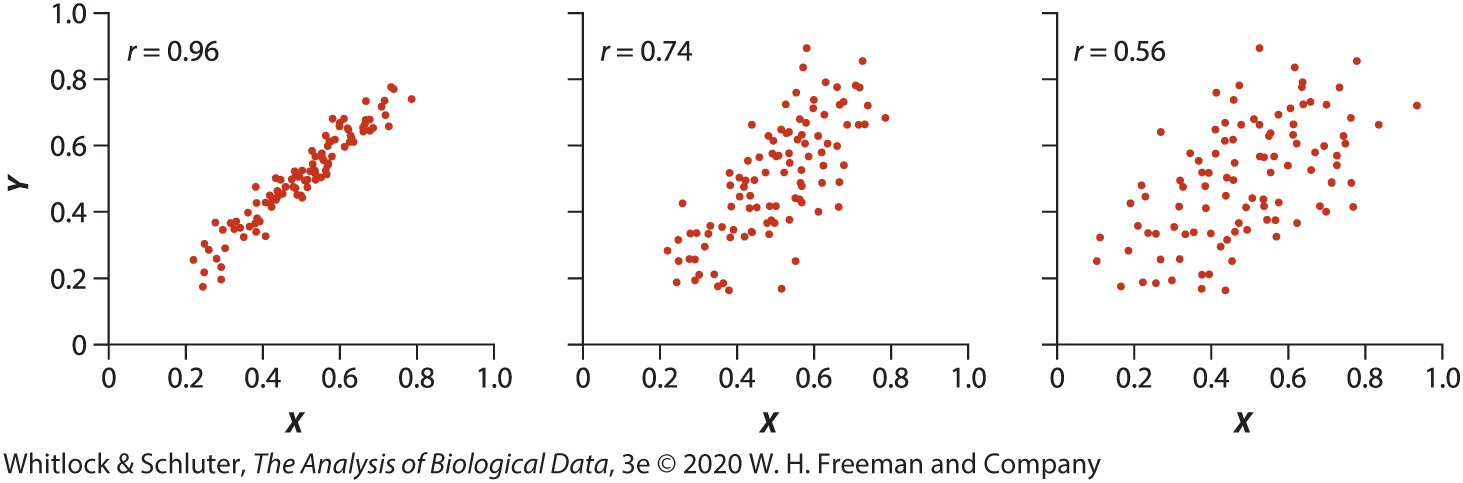
Strength of correlation
- Strength describes how closely the points follow a linear trend
- Stronger correlation: points cluster tightly around a line
- Weaker correlation: points show more scatter around the line
Linear correlation coefficient \(r\)
- Measures the strength and direction of association between two numerical variables
- Population corr. = \(\rho\) , sample corr. = \(r\)
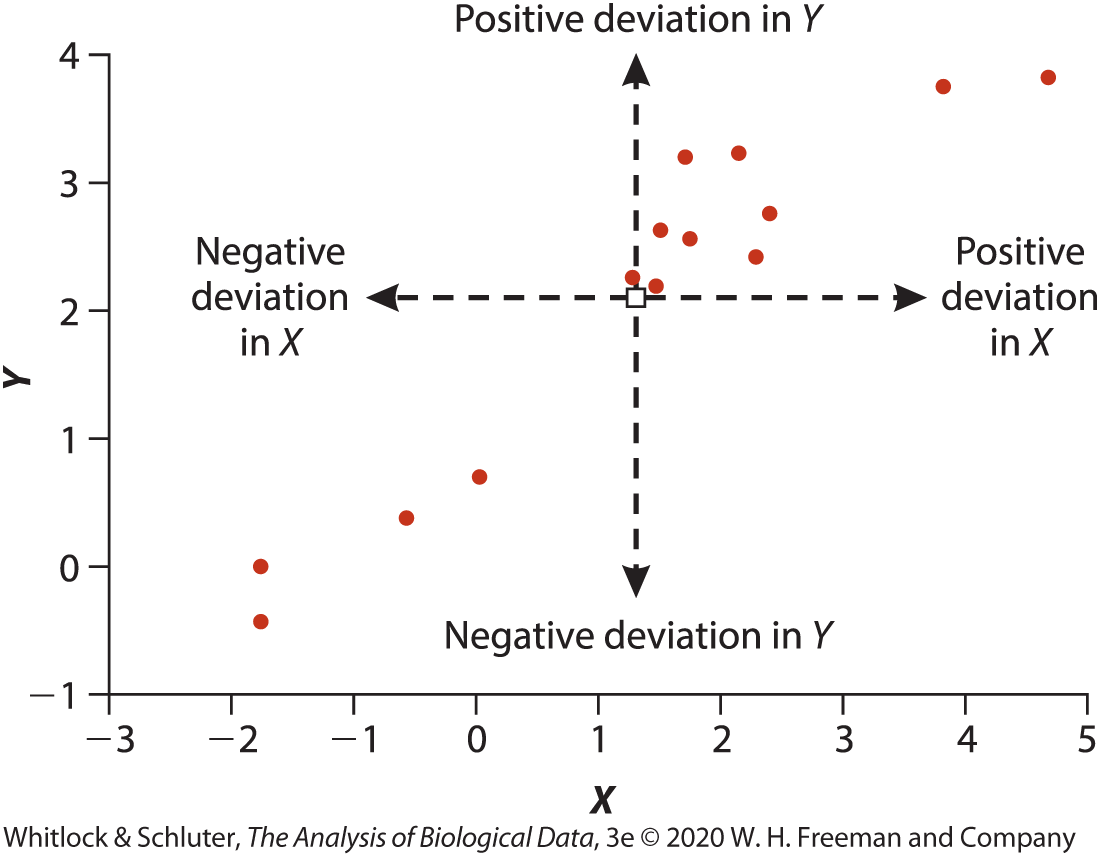
- Based on paired deviations from X and Y means
- Points in the upper-right and lower-left quadrants contribute positive correlation
- Values range from \(-1\) to \(+1\)
\[ r = \frac{\sum (X_i-\bar{X})(Y_i-\bar{Y})} {\sqrt{\sum (X_i-\bar{X})^2 \sum (Y_i-\bar{Y})^2}} \]
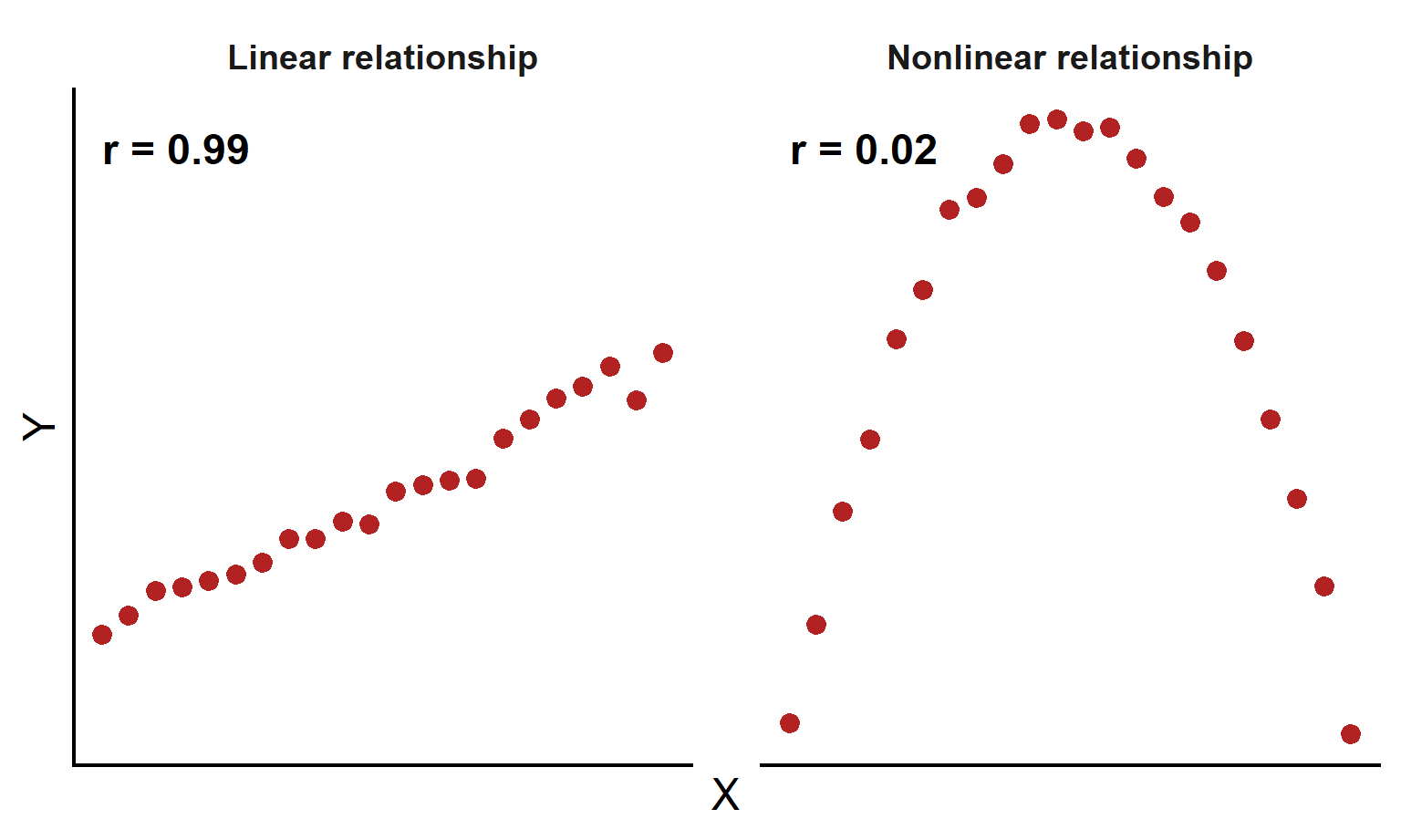
Correlation measures linear relationships
- Pearson’s correlation describes how closely points follow a straight-line trend
- A strong linear pattern can produce a large positive or negative \(r\)
- A curved relationship may have \(r\) near 0 even when X and Y are strongly related
- Always inspect a scatterplot before interpreting \(r\)
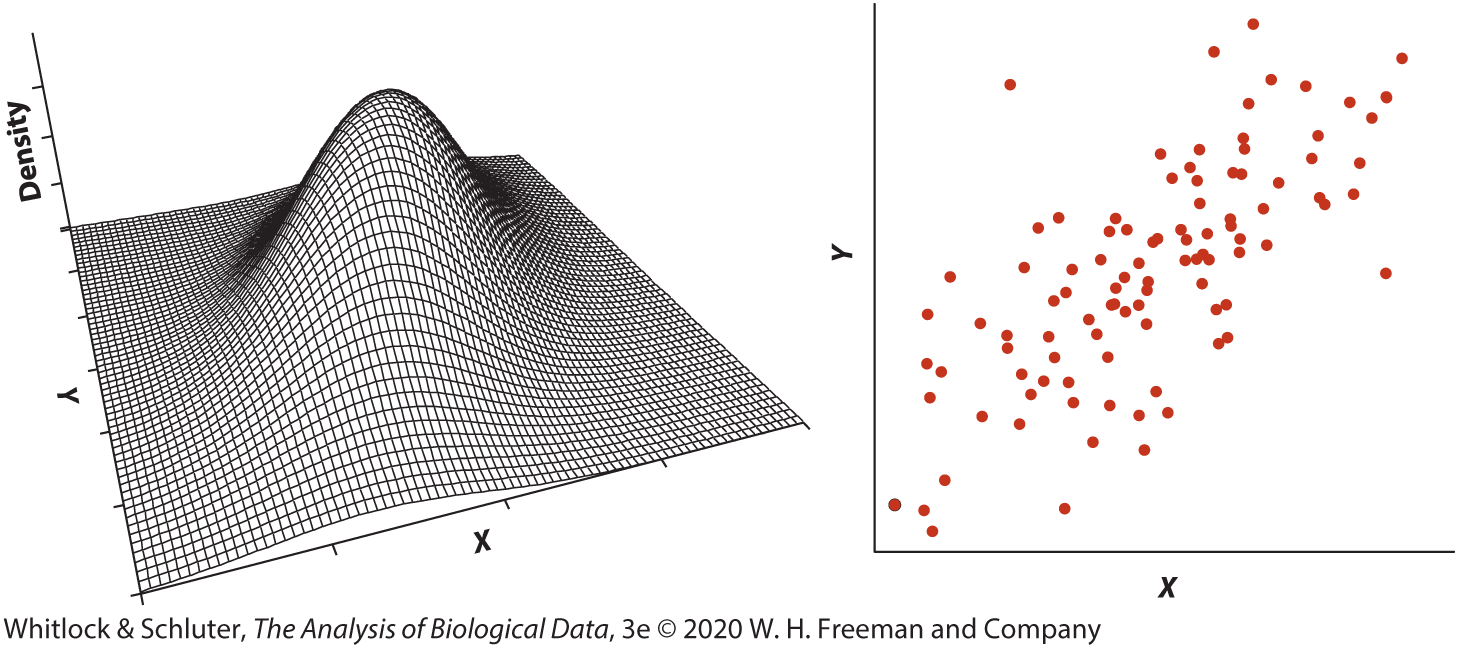
Assumptions of Pearson correlation
- Observations are an independent random sample from the population
- The relationship between X and Y is approximately linear
- The scatter of points forms an elliptical cloud without extreme outliers
- X and Y are each approximately normally distributed
- A scatterplot is the best first check of these assumptions
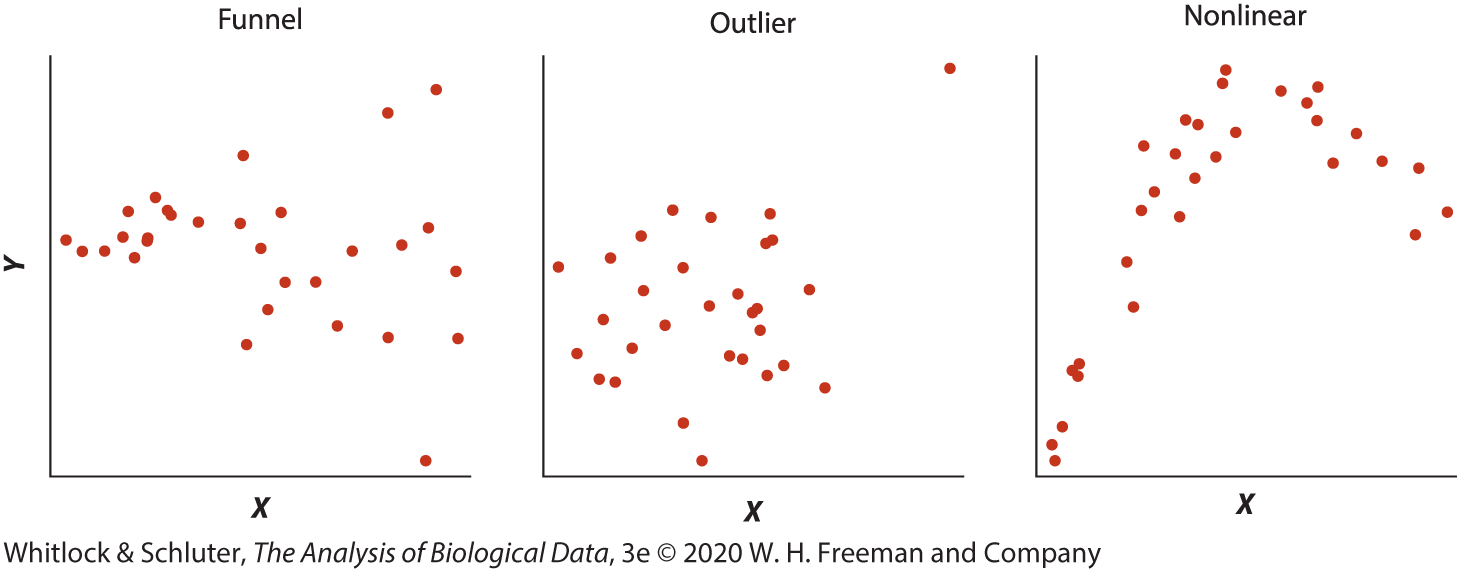
Common departures from assumptions
- Funnel shape: spread changes across X (heteroscedasticity)
- Outliers: unusual points can strongly influence r
- Nonlinear pattern: curved relationships are not described well by Pearson correlation
- Inspect scatterplots before interpreting or testing correlation
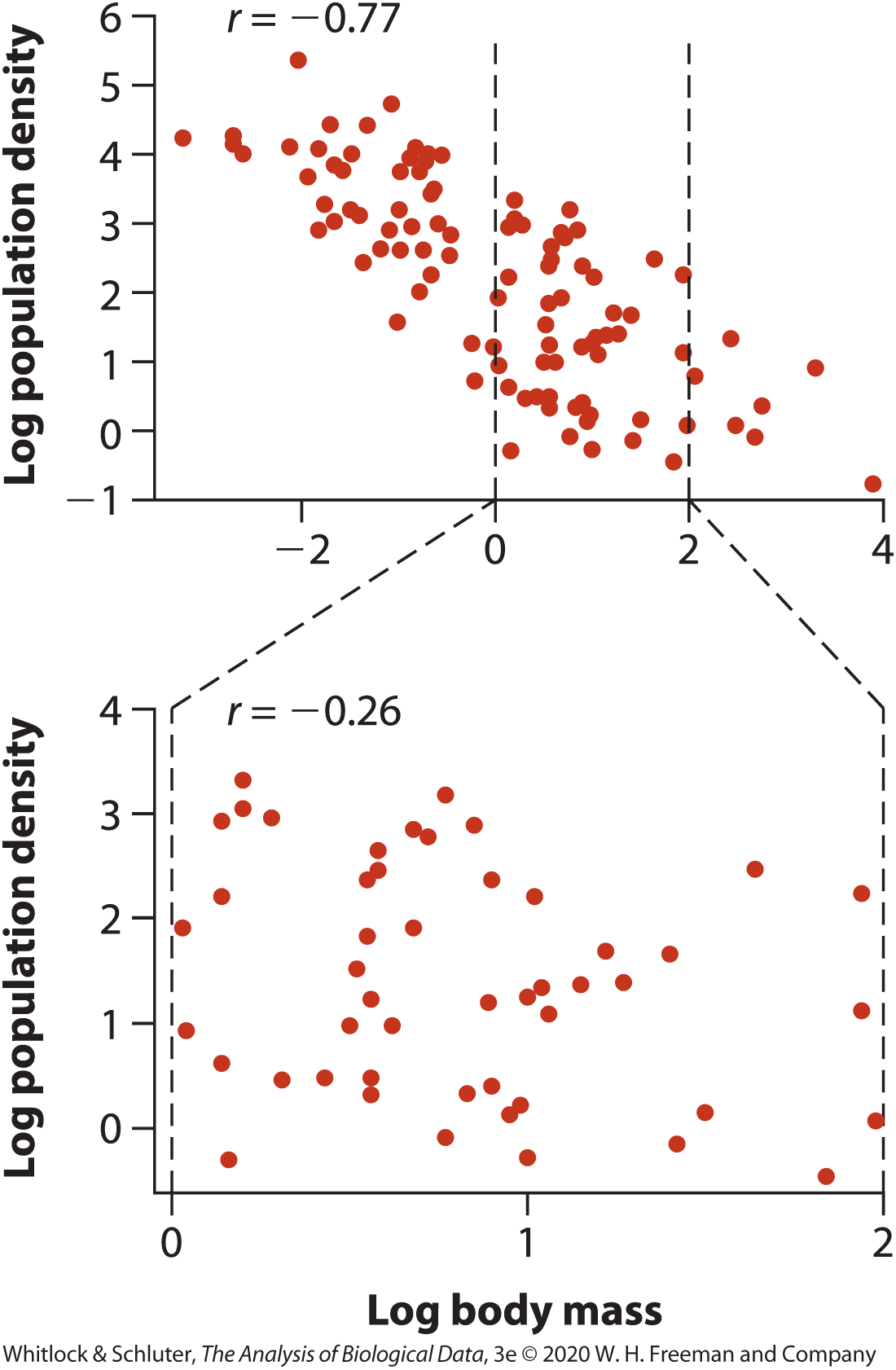
Correlation depends on the range of values
- Correlation can become weaker when the range of X values is restricted
- In the full dataset, body mass and population density show a strong negative correlation
- Using only species with intermediate body masses reduces the range and lowers \(r\)
- Correlations from different studies may not be comparable if they use different ranges of data
- Always consider the range of included observations when interpreting \(r\)
Measurement error weakens correlation
- Measurement error adds random noise to X, Y, or both variables
- Random measurement error usually makes the observed correlation closer to 0
- This bias toward zero is called attenuation
- Better measurement methods and repeated measurements can reduce this problem
- Weak observed correlations may partly reflect poor measurement quality
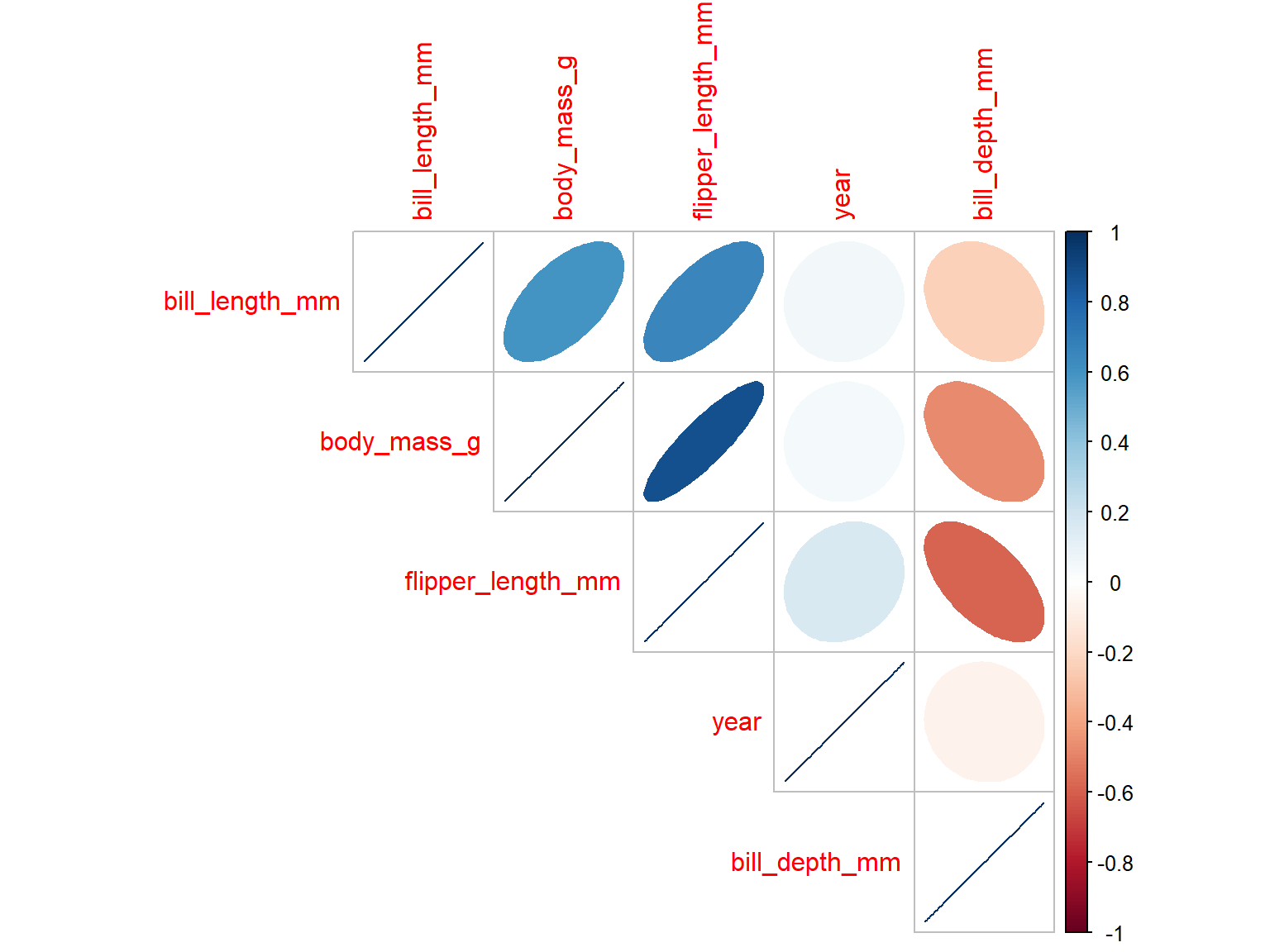
Correlation matrices
- When a dataset has many numerical variables, we can calculate all pairwise correlations at once
- A correlation matrix summarizes the correlation between every pair of variables
corrplot()displays the matrix using colors, circles, or numbers- Larger and darker symbols indicate stronger correlations
- Useful for exploring patterns before building models