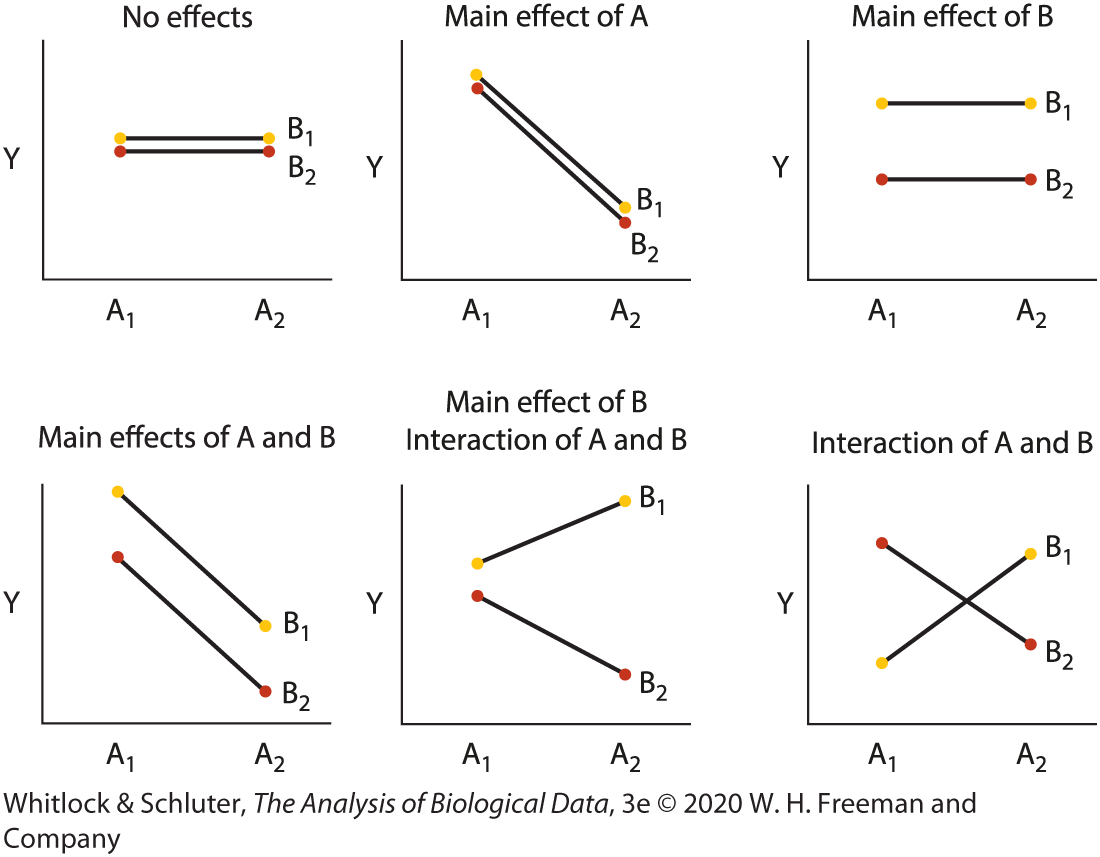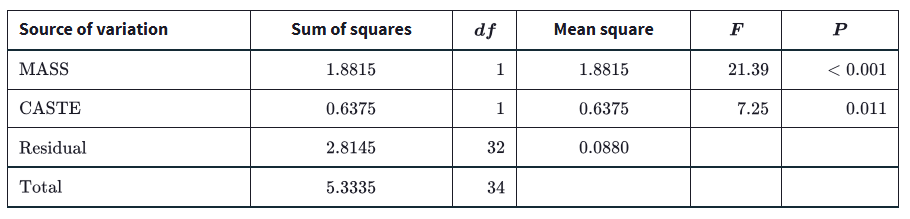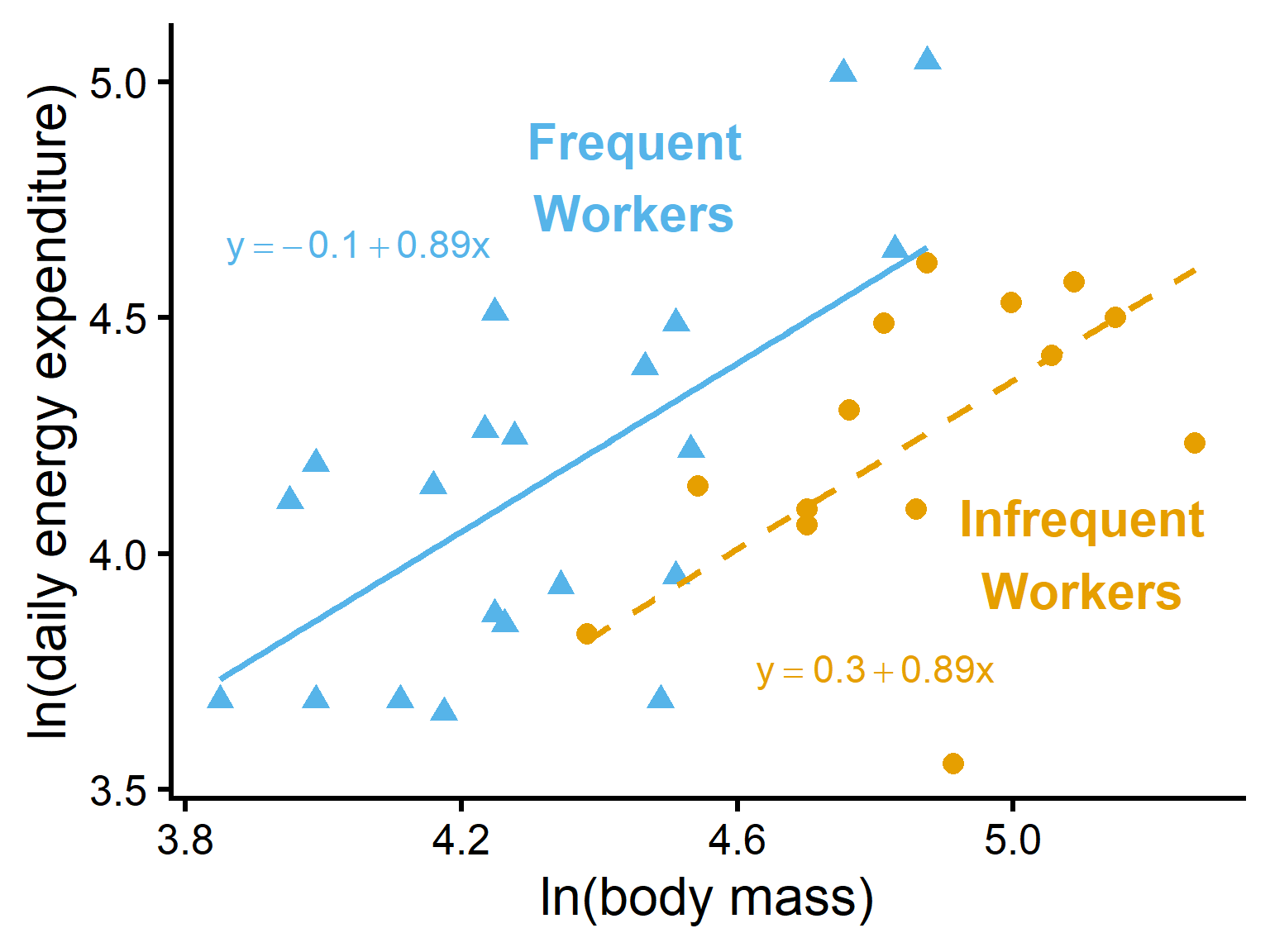
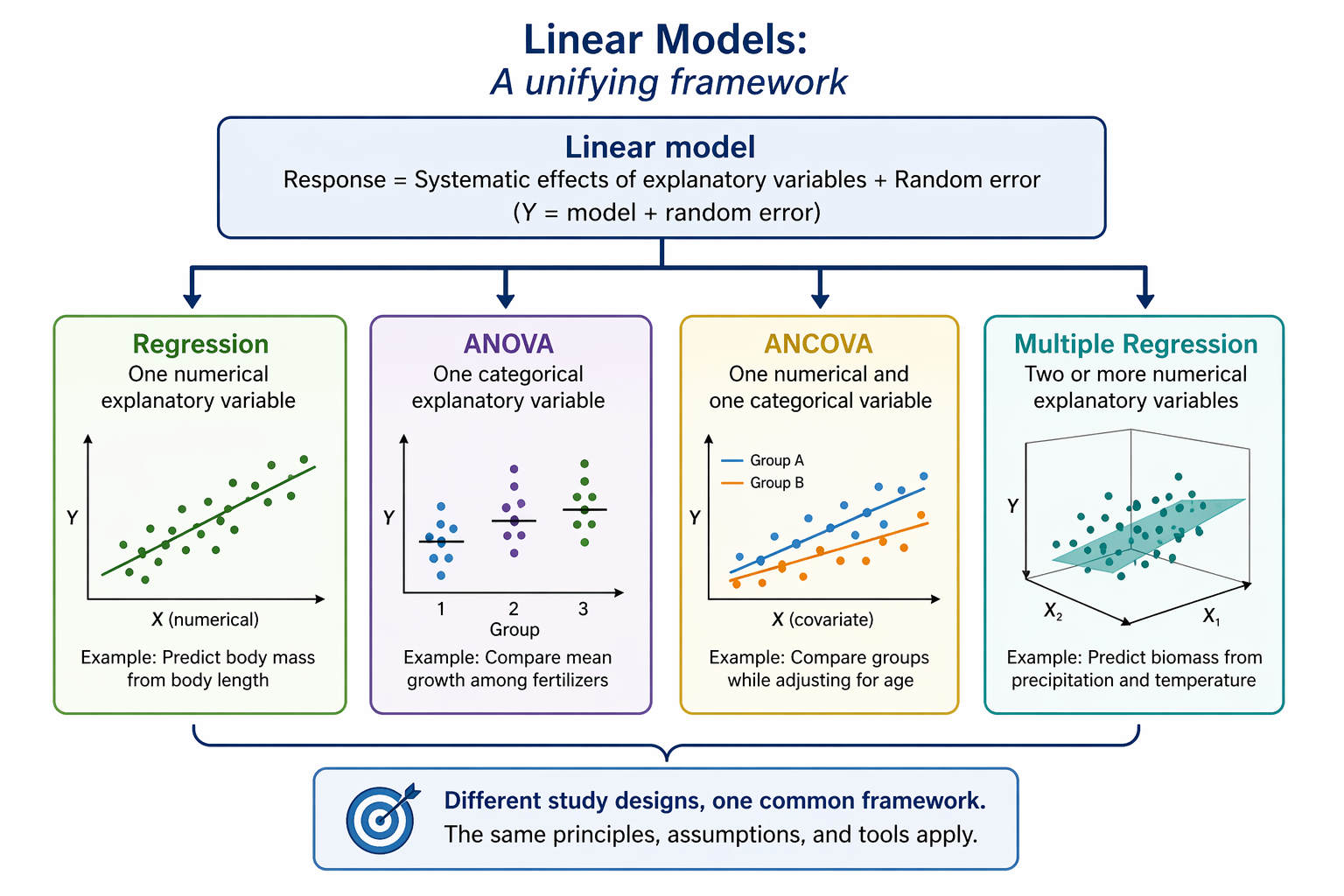
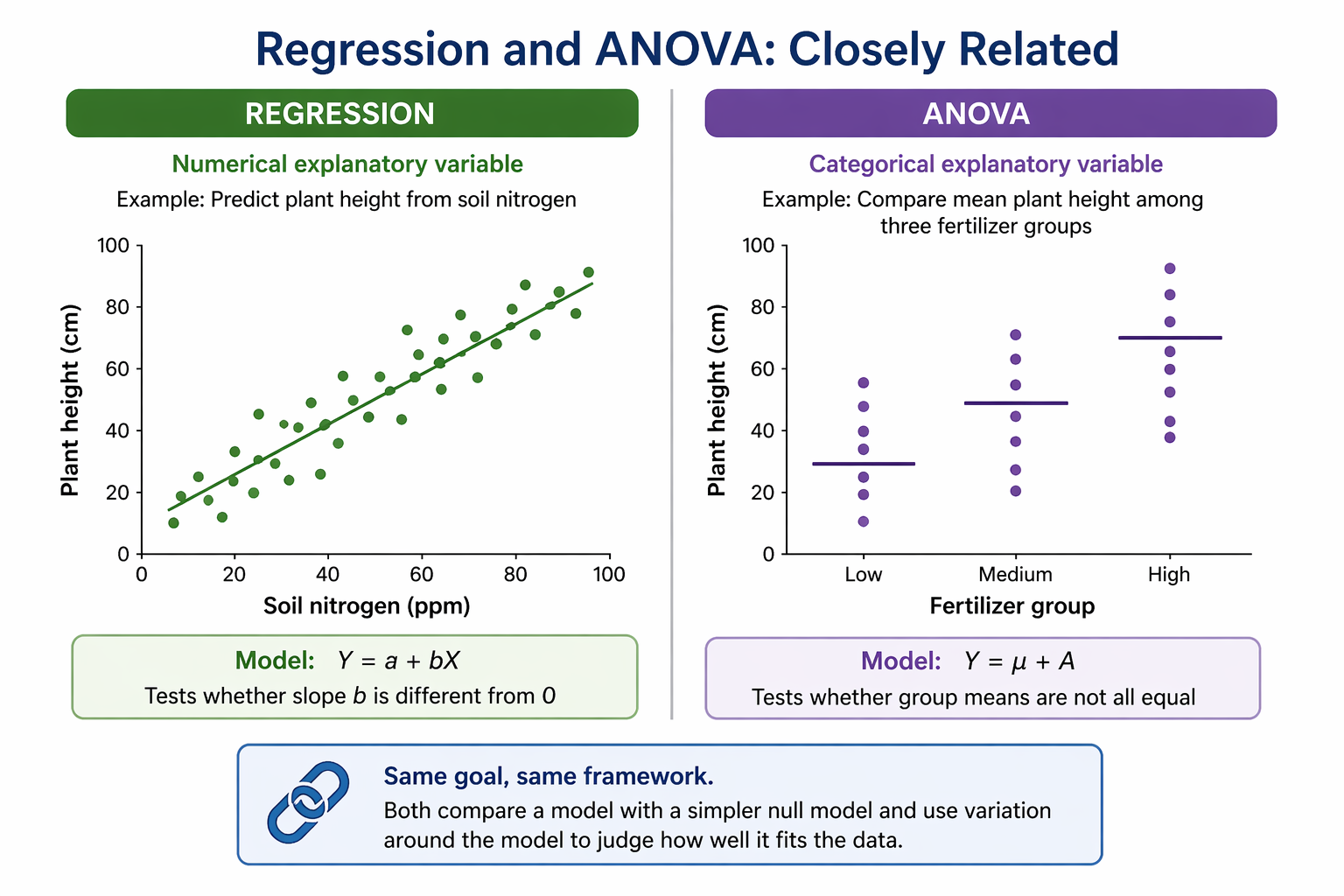
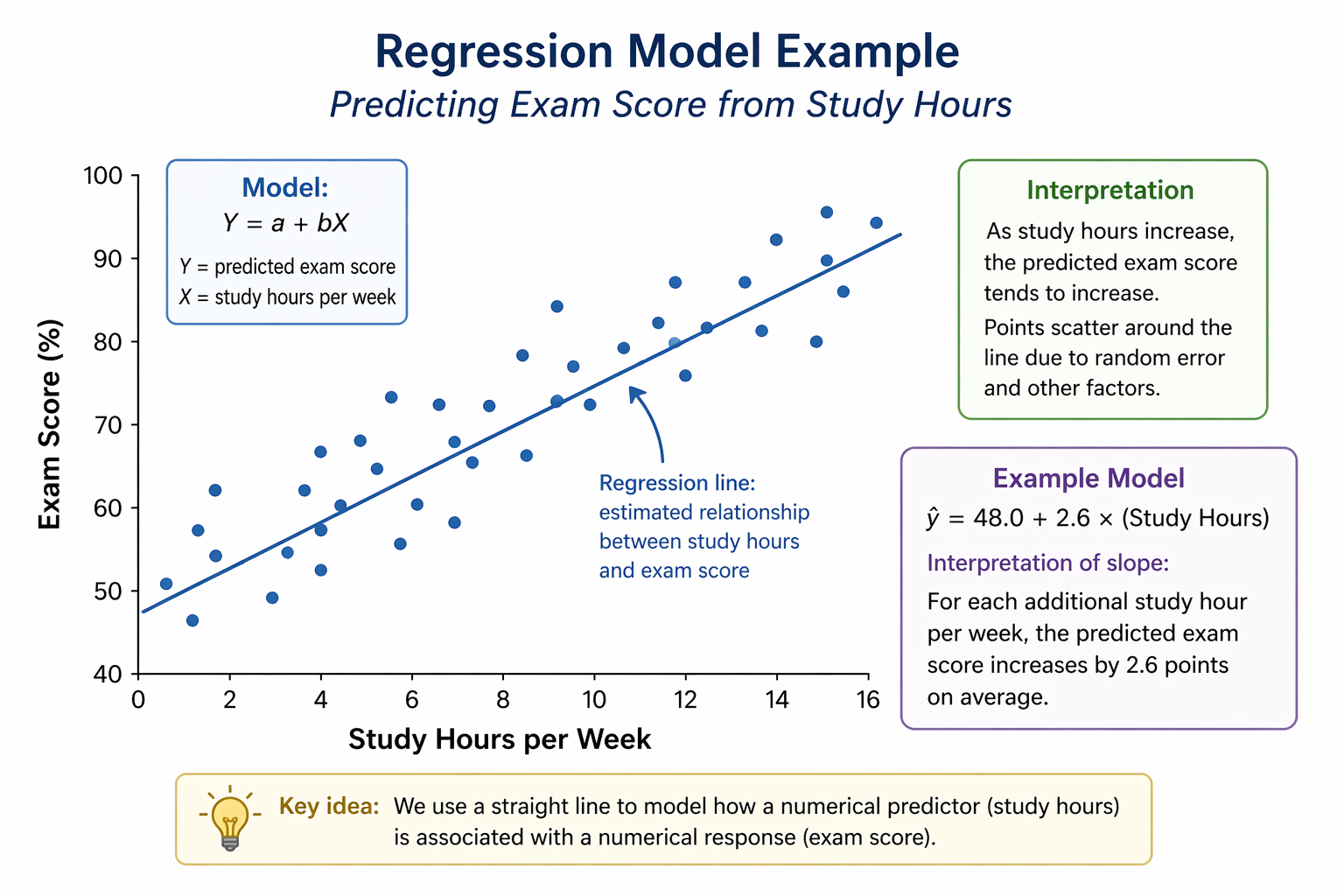
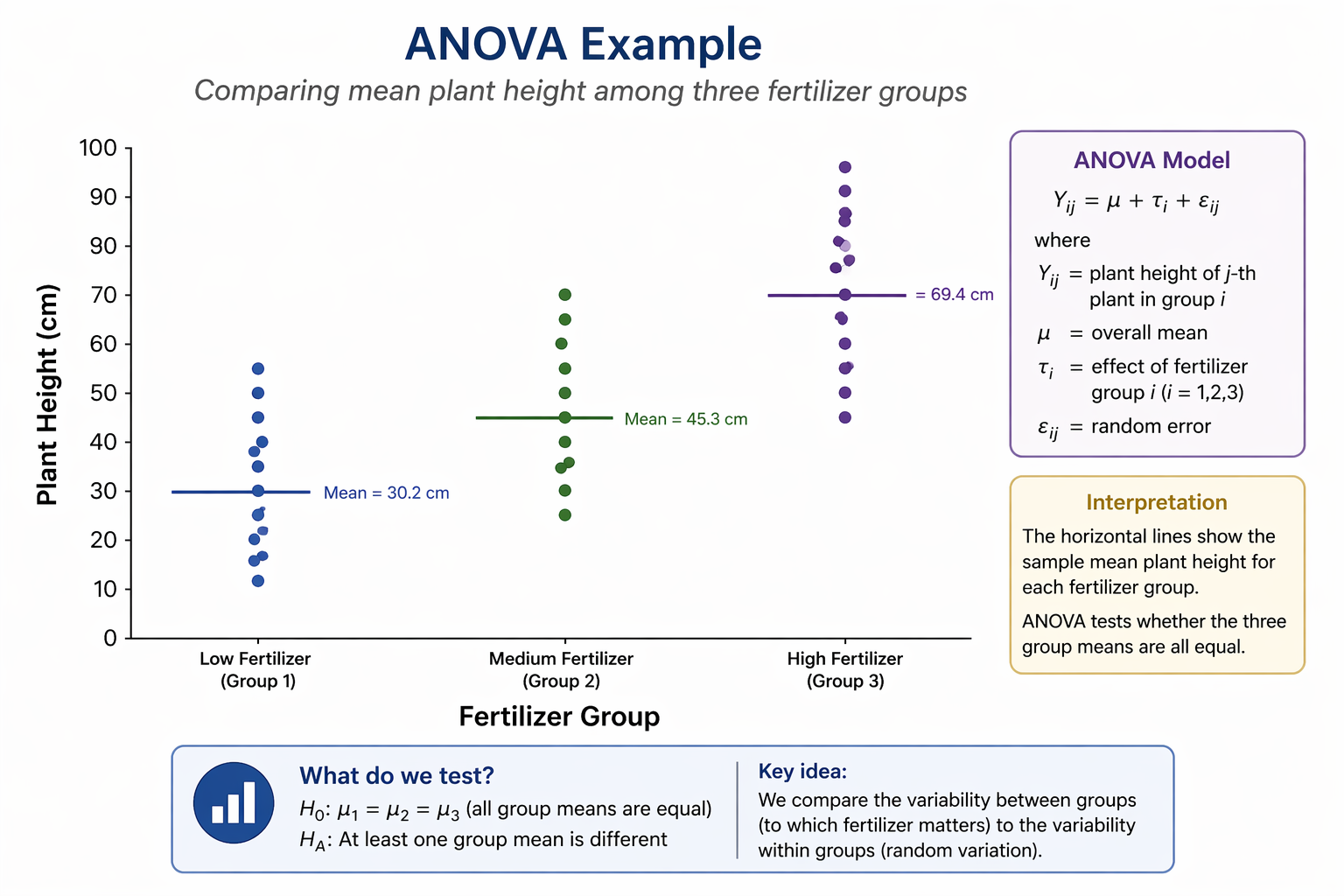
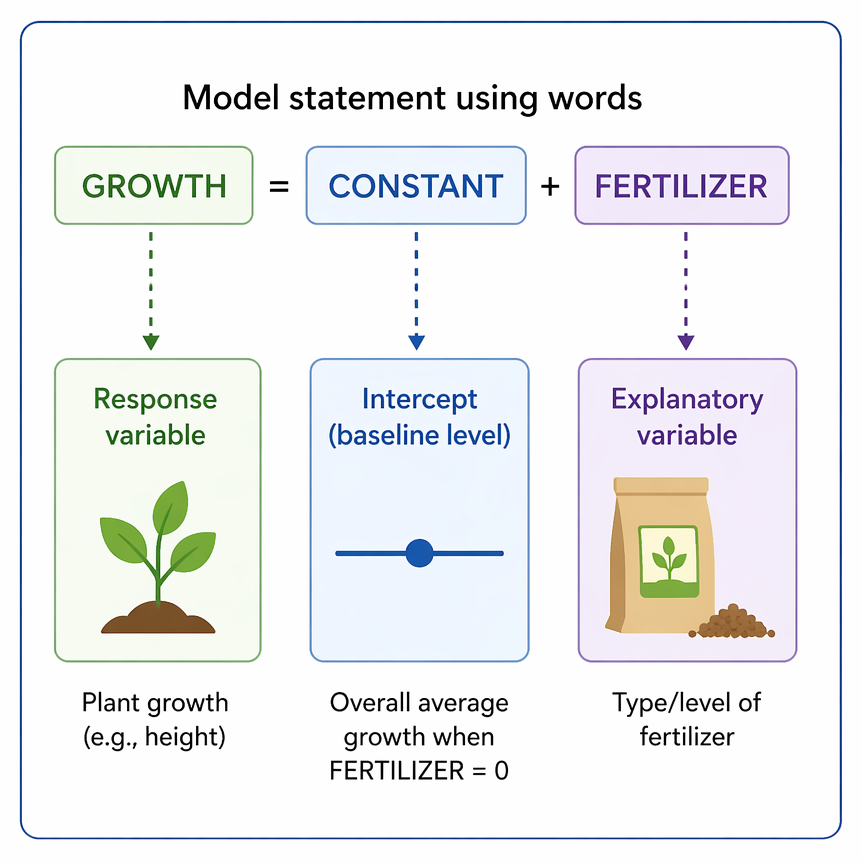
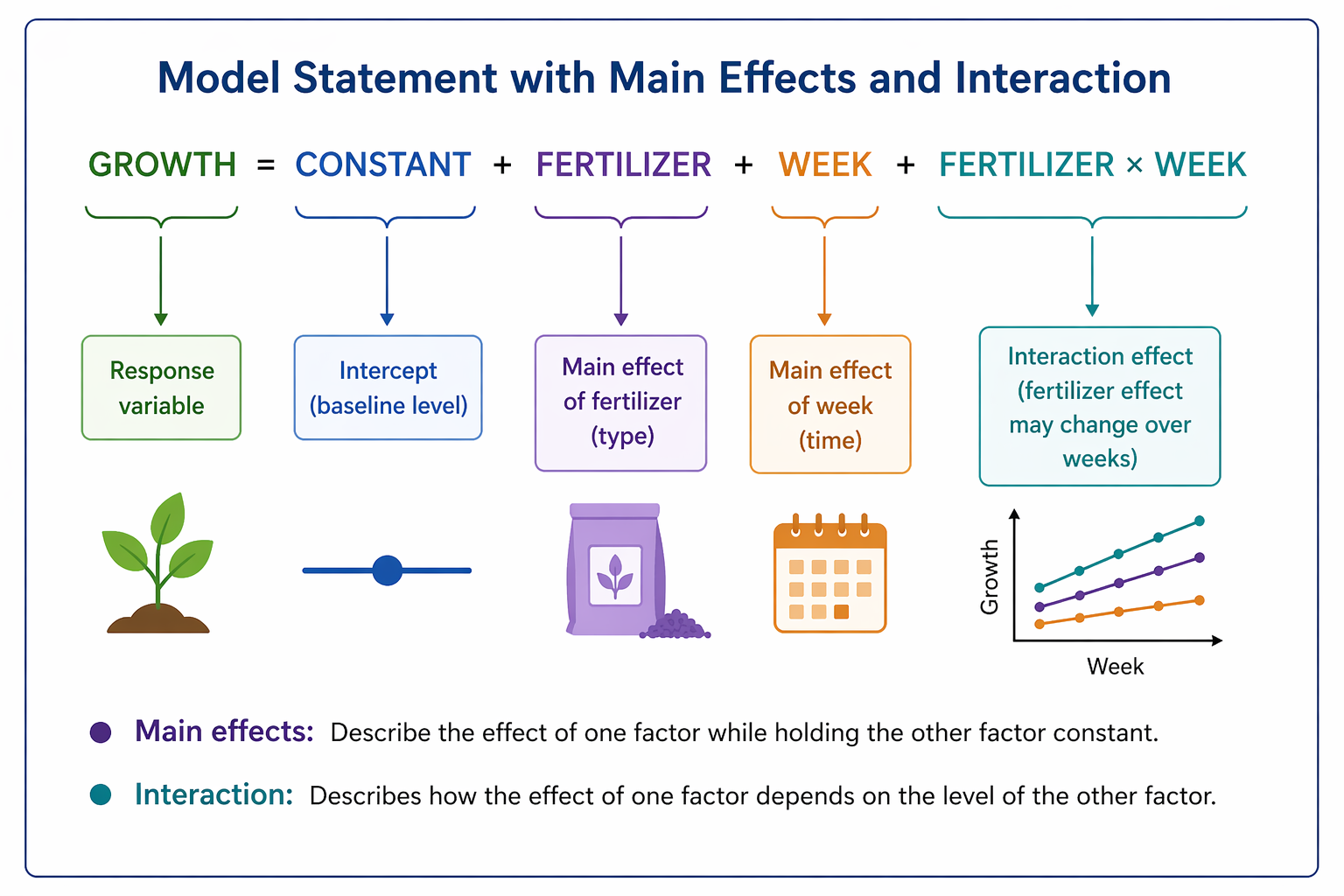
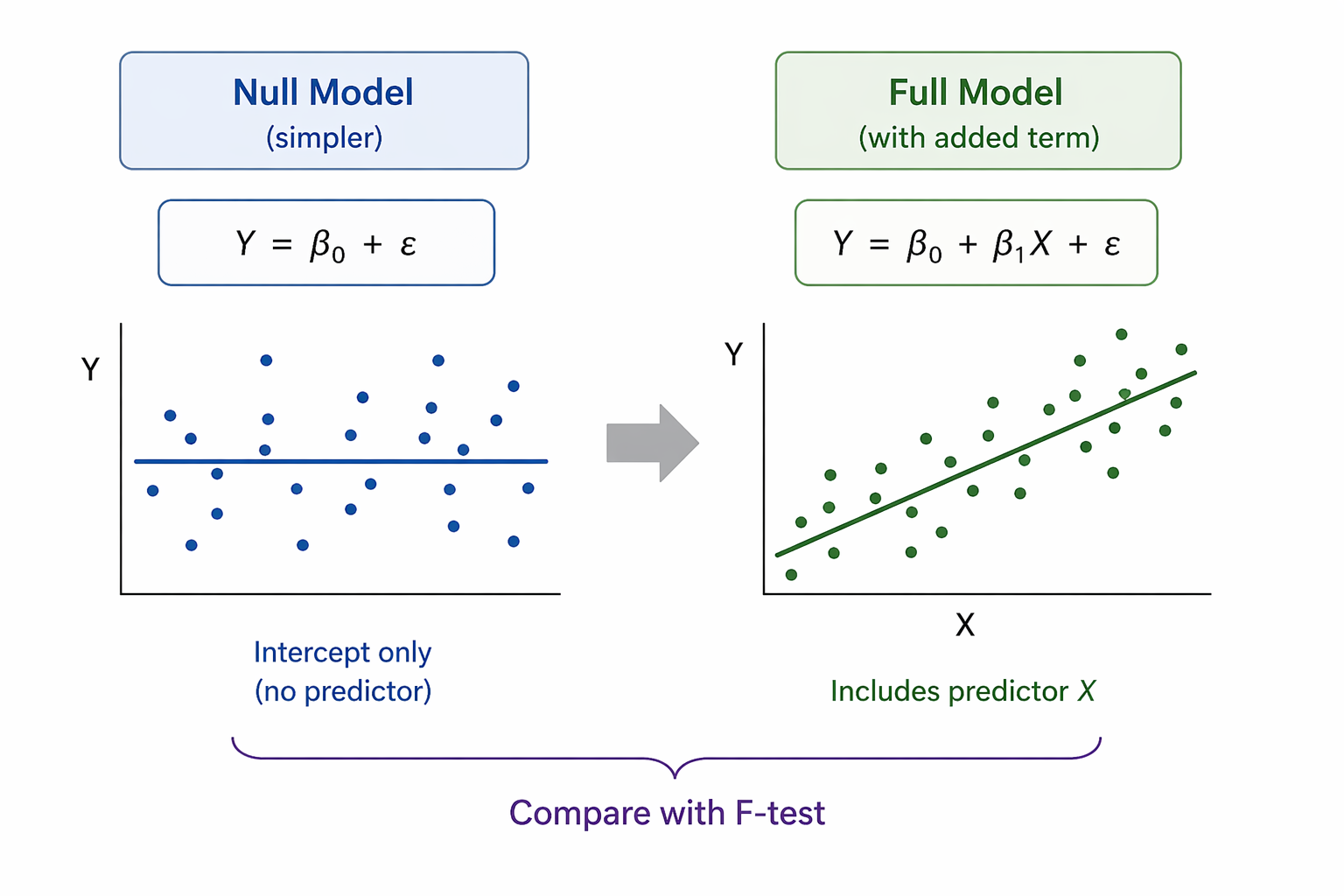
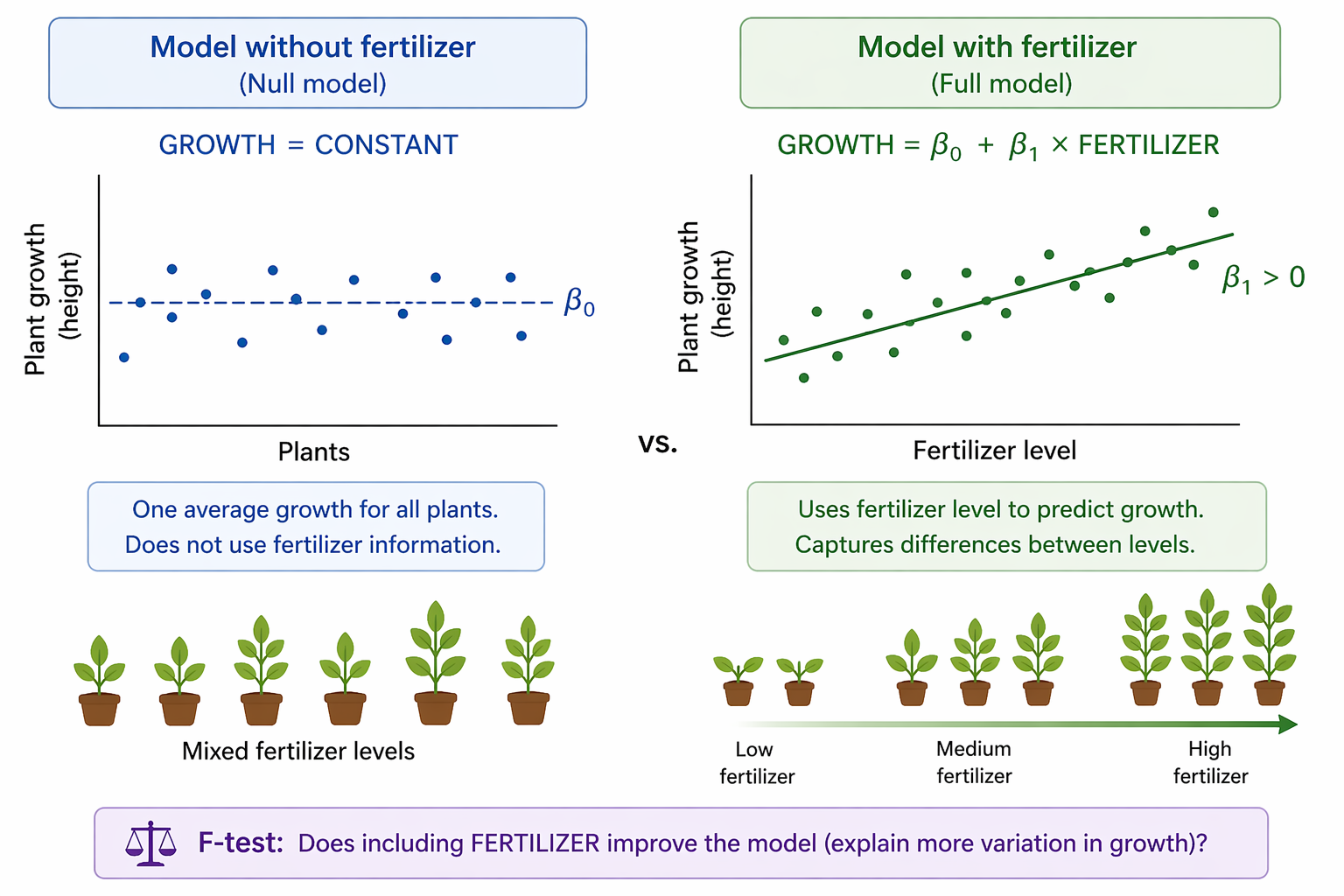
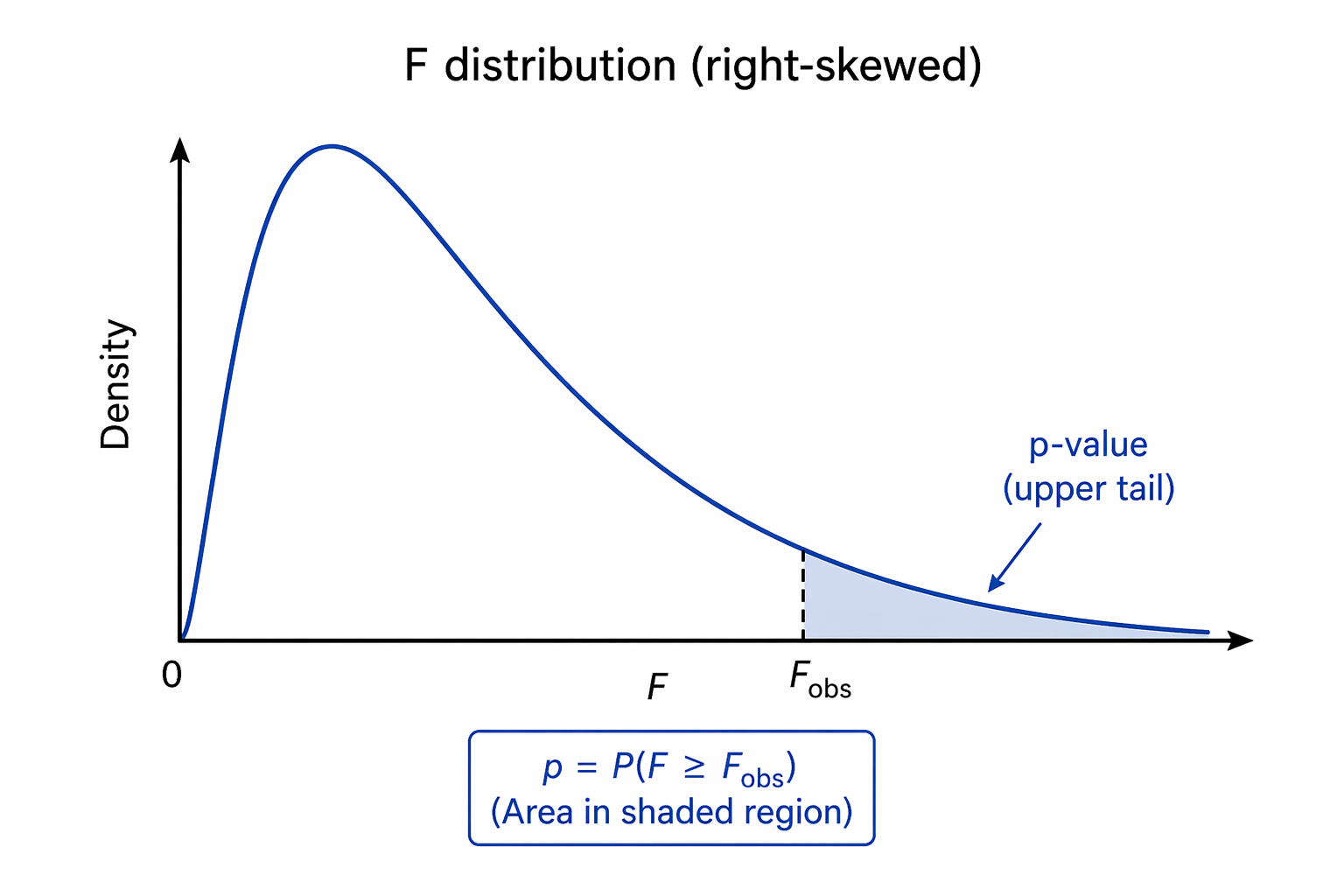


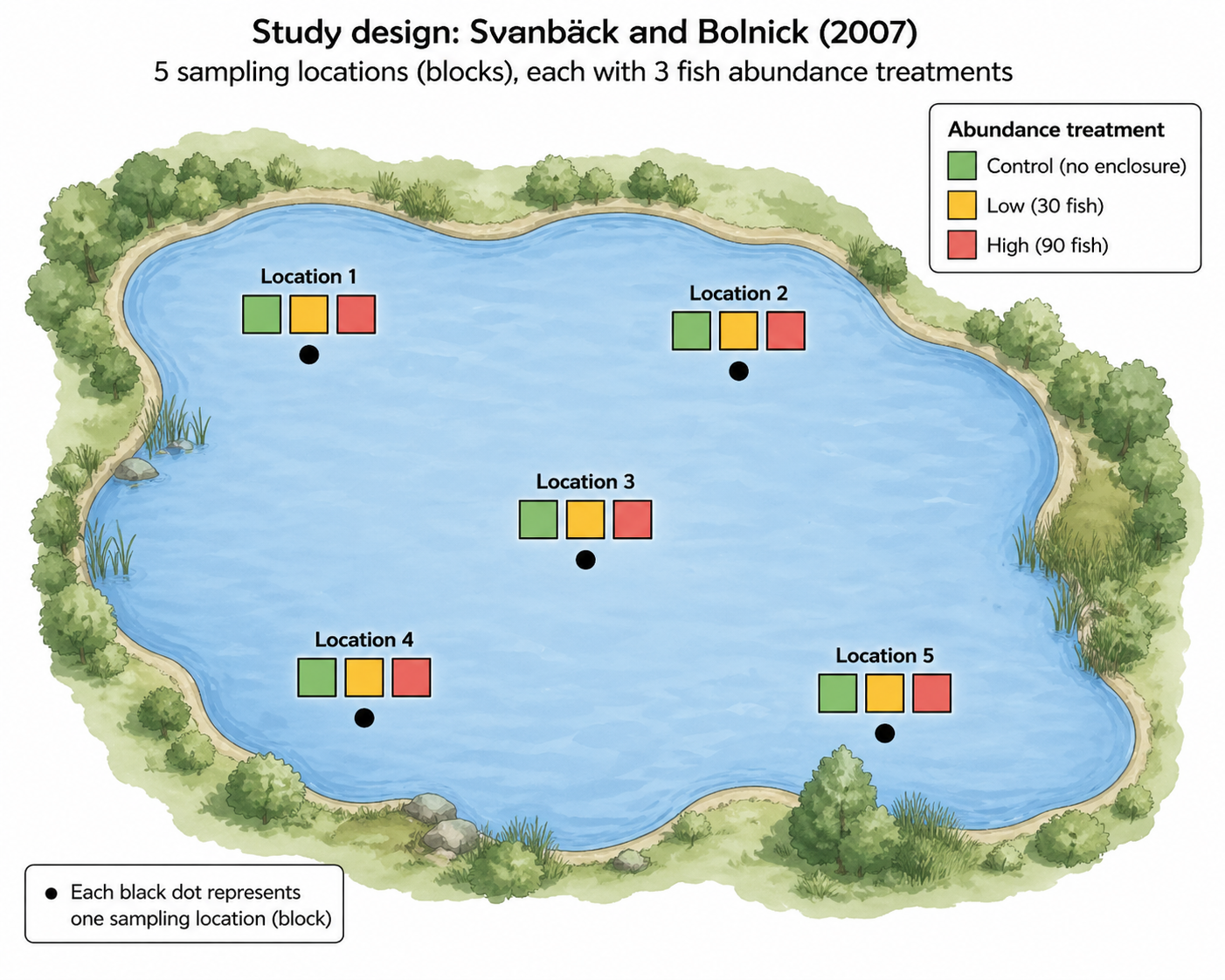
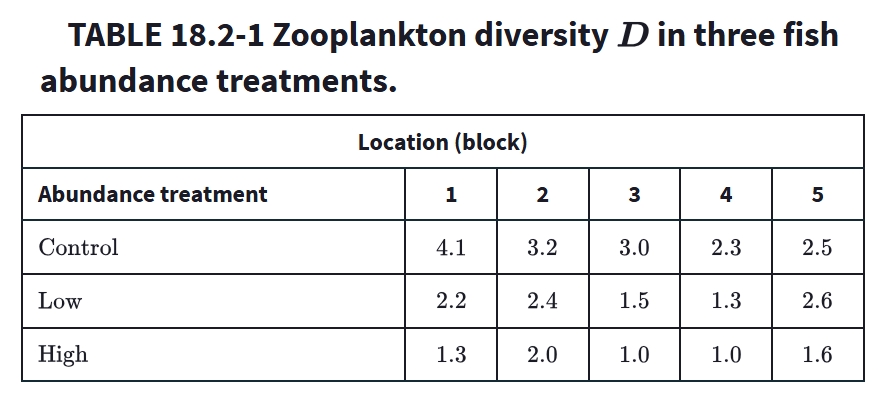
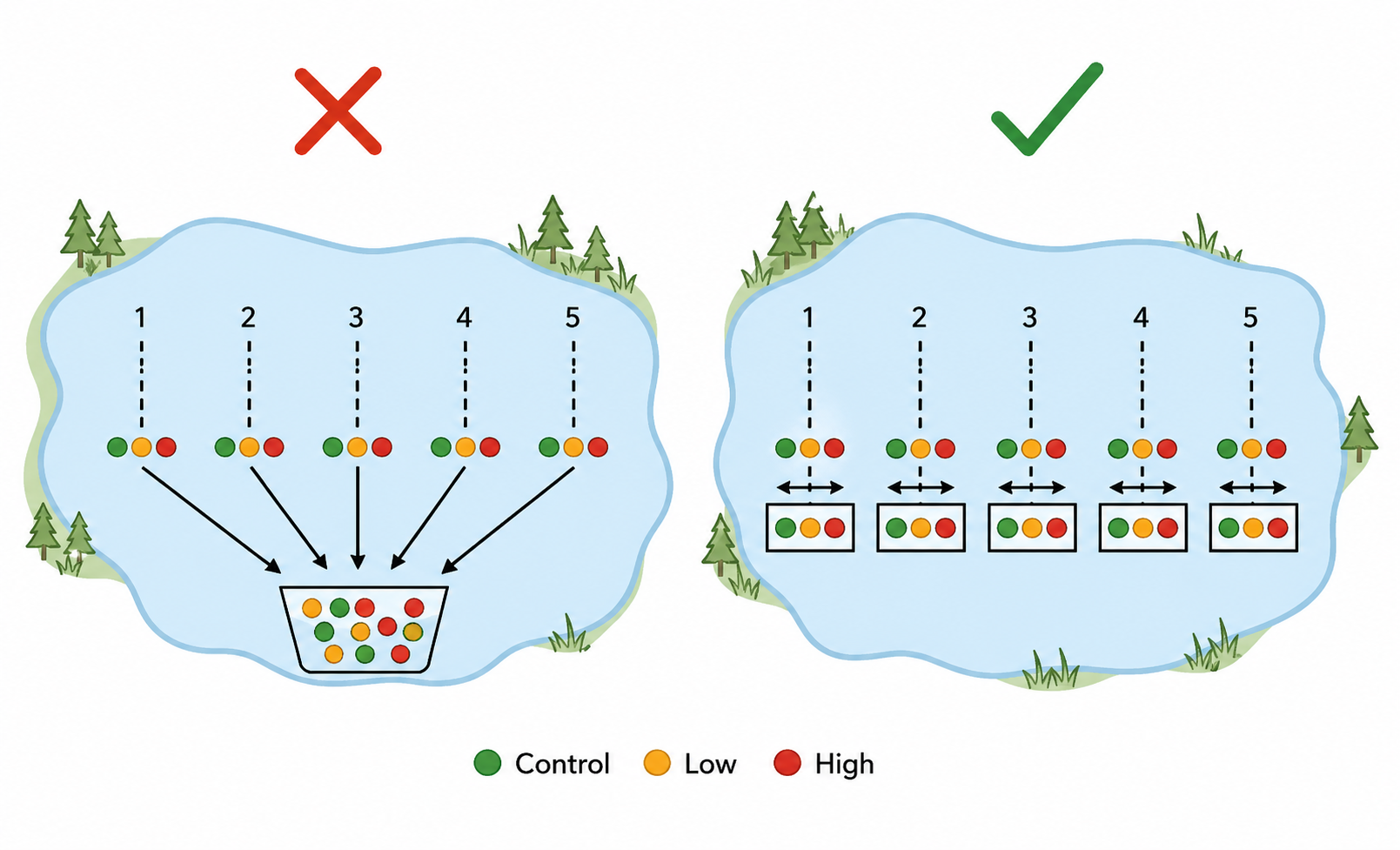
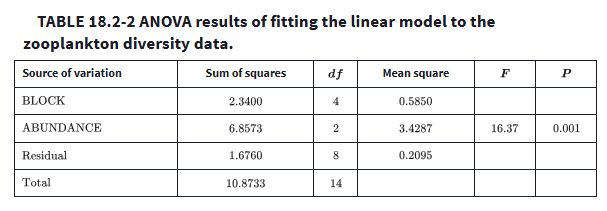
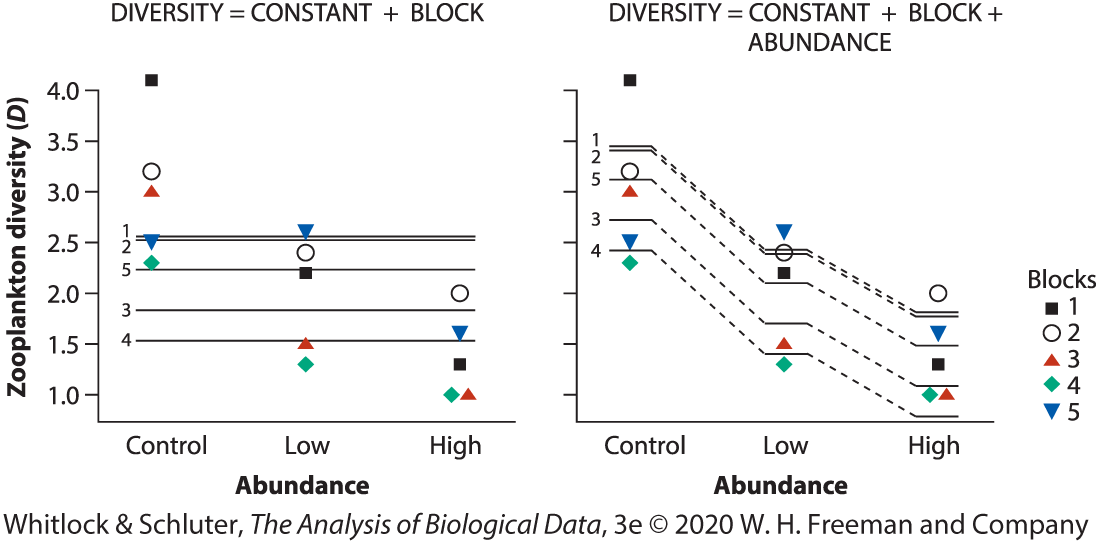

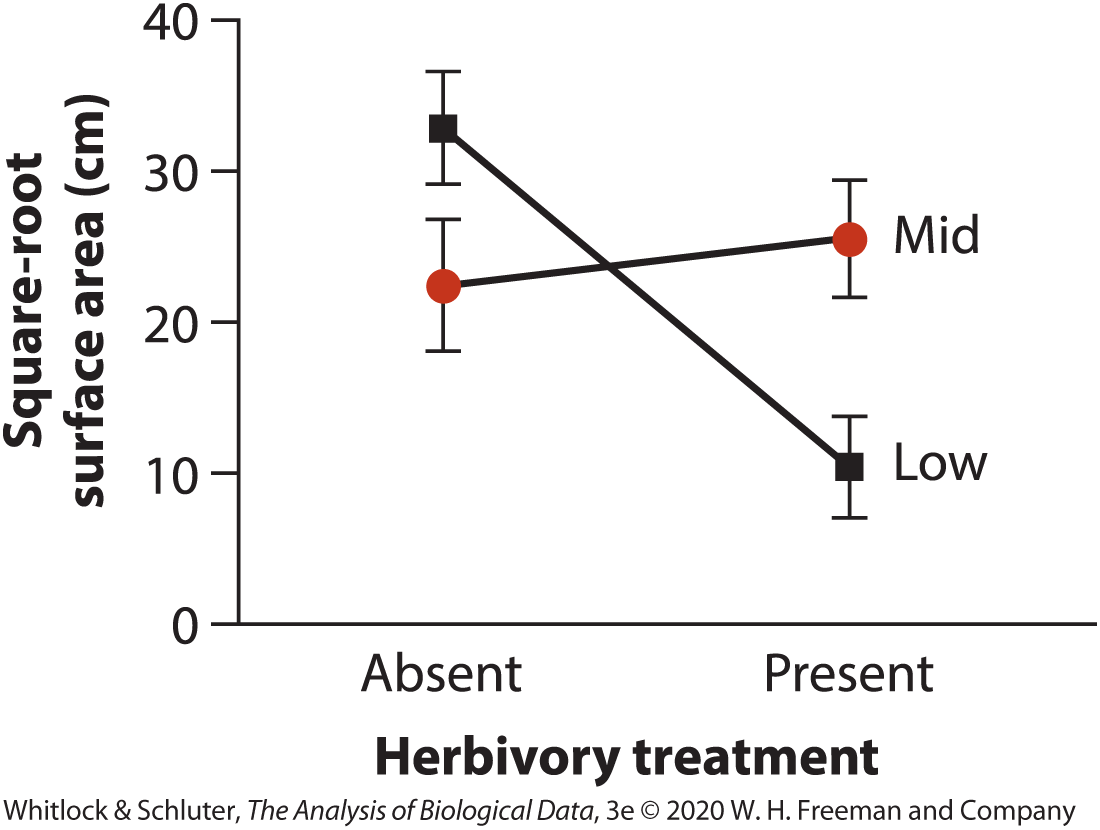
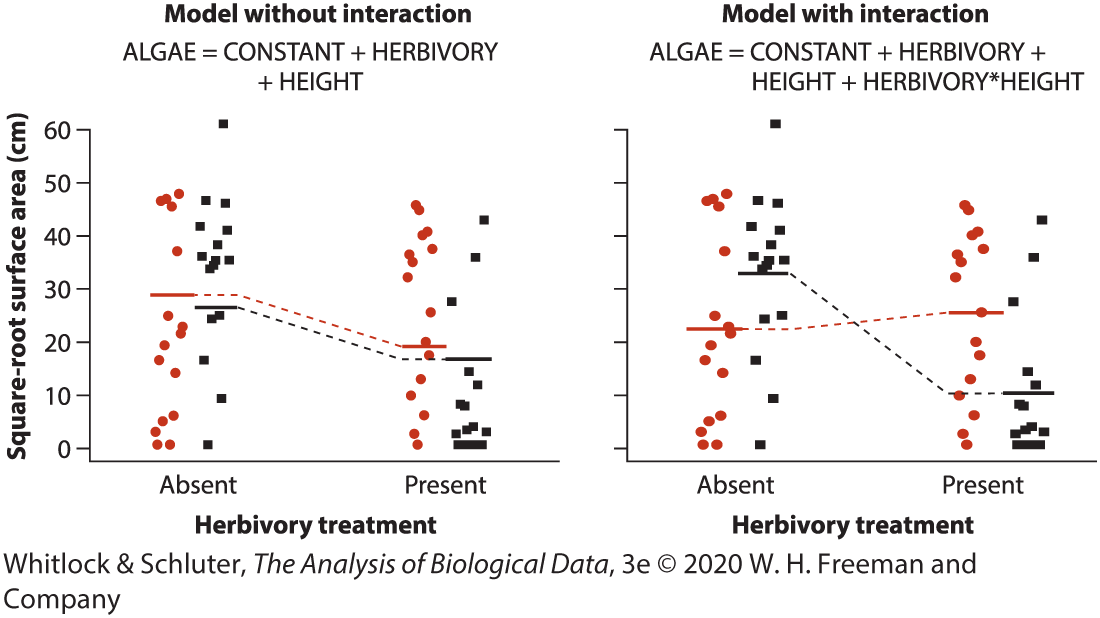
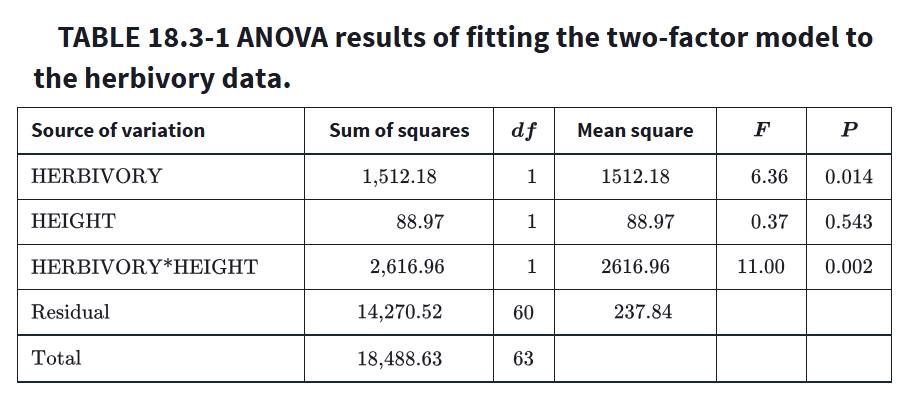

Main effects vs interaction
Main effect: average effect of one factor across levels of the other factor
Interaction: effect of one factor depends on the level of the other factor
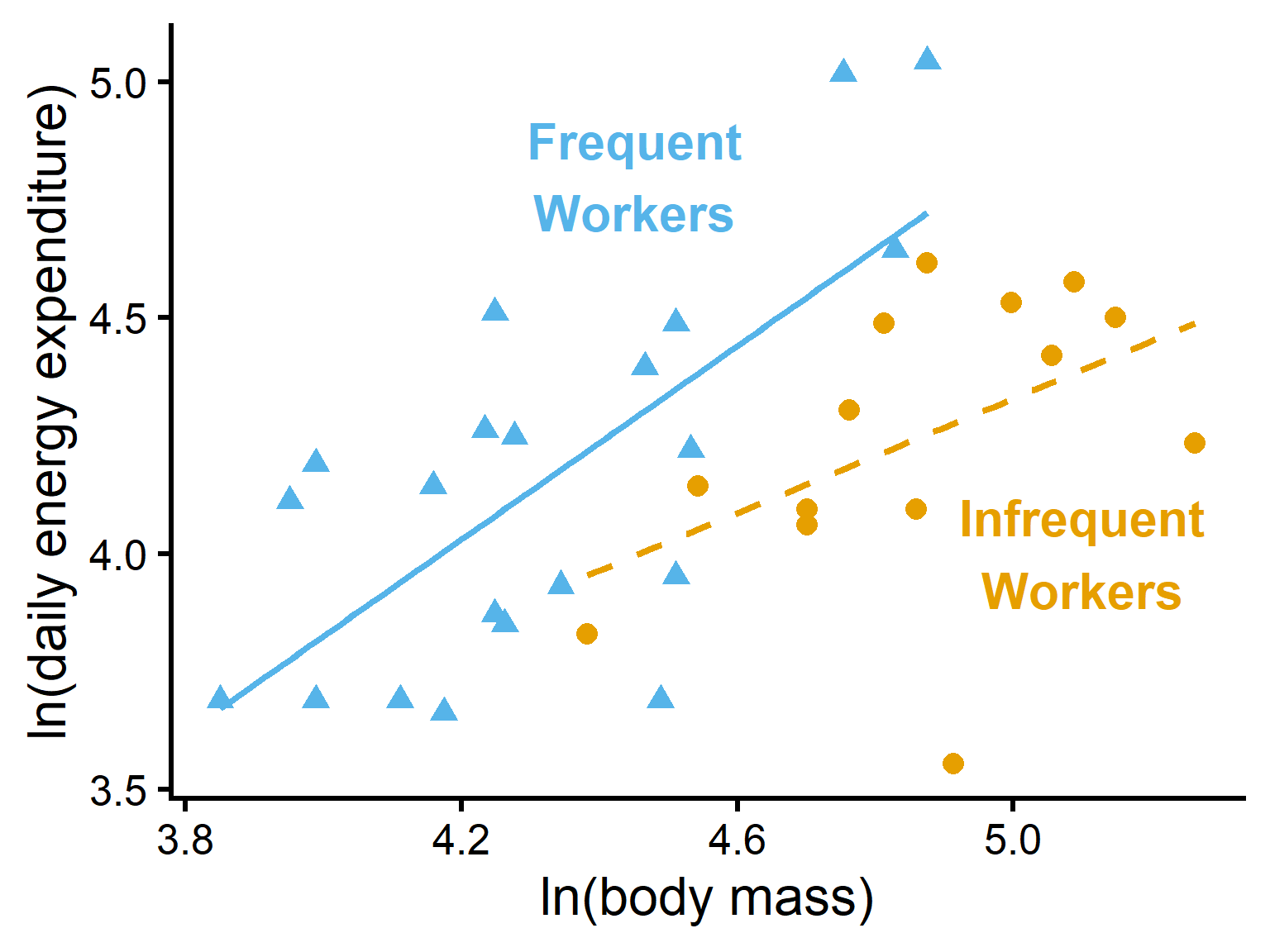
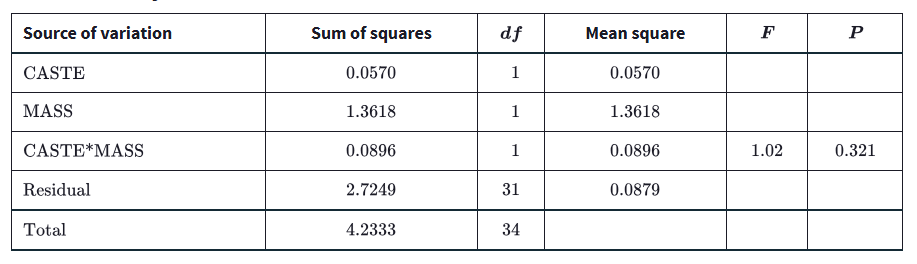
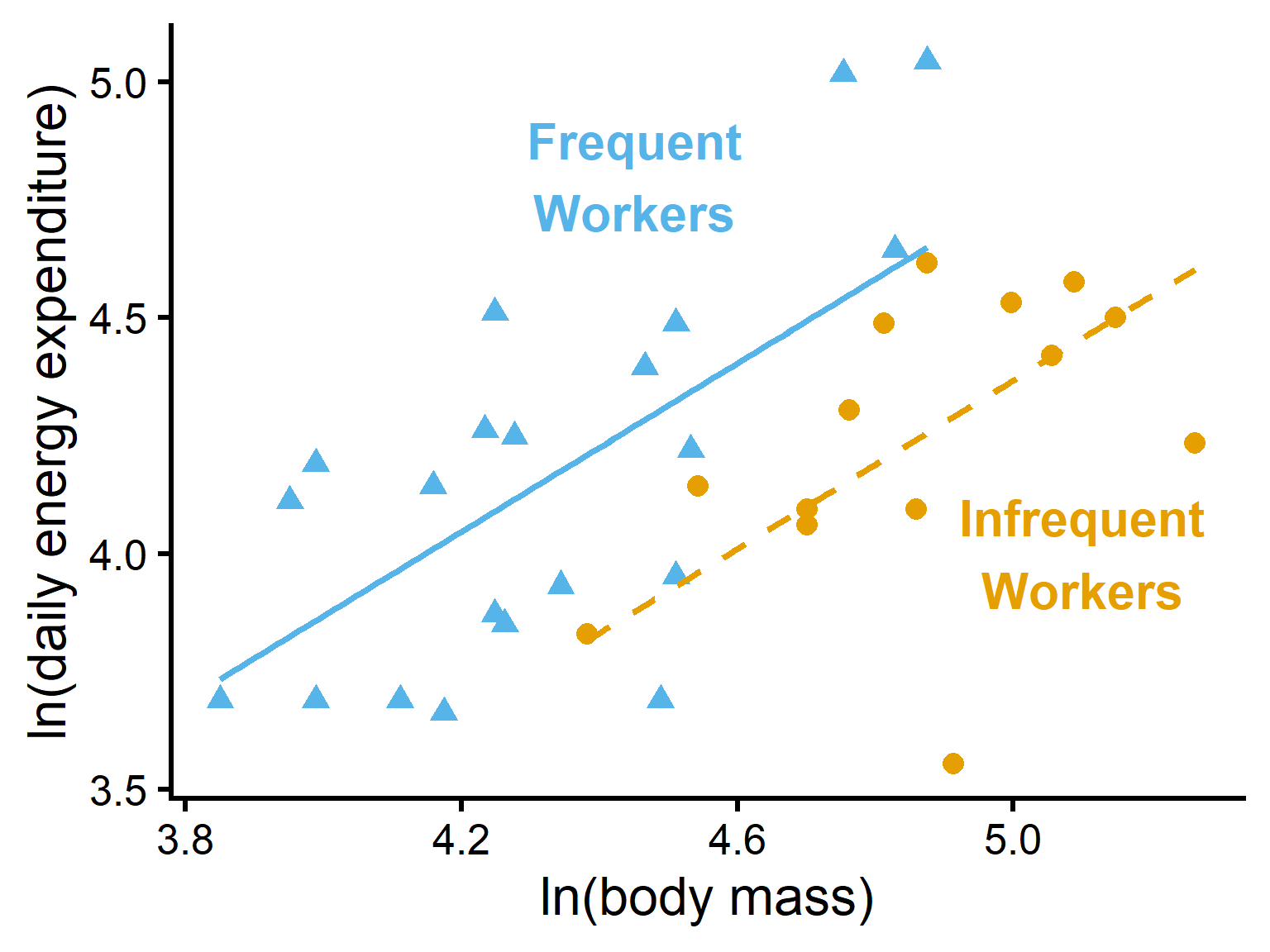
In interaction plots:
parallel lines suggest no interaction
nonparallel lines suggest interaction