# A tibble: 2 × 8
sex n_sex n_total p_hat se p_prime ci_lower ci_upper
<fct> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 male 168 333 0.505 0.0274 0.504 0.451 0.558
2 female 165 333 0.495 0.0274 0.496 0.442 0.549
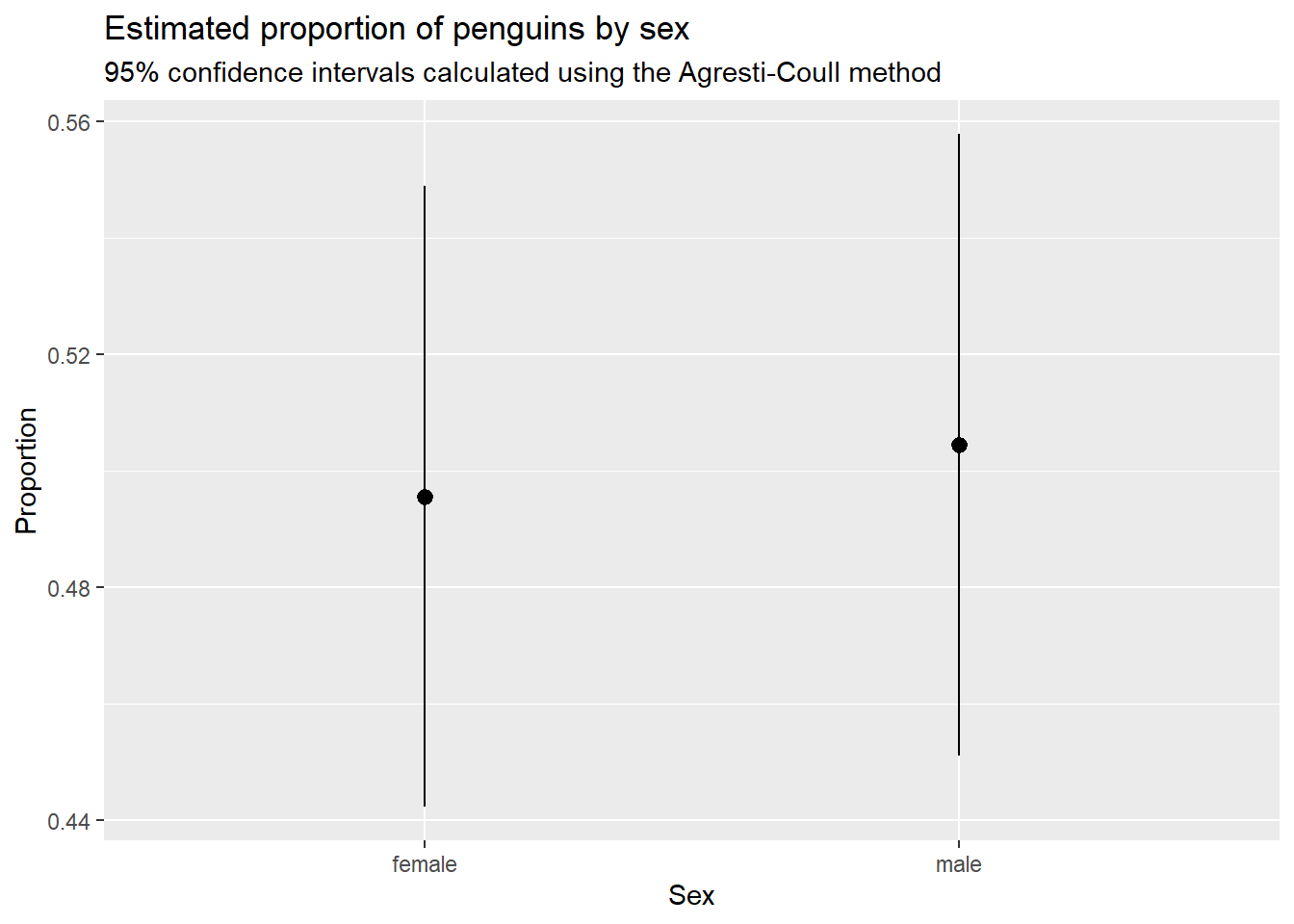
# Graph estimates and CIs ----ggplot(penguins_summary)+geom_pointrange(aes(x =sex, y =p_hat, ymin =ci_lower, ymax =ci_upper))+labs( x ="Sex", y ="Proportion", title ="Estimated proportion of penguins by sex", subtitle ="95% confidence intervals calculated using the Agresti-Coull method")
# Hypothesis test ----n_female<-penguins_summary|>filter(sex=="female")|>pull(n_sex)n_total<-penguins_summary|>filter(sex=="female")|>pull(n_total)prop.test(x =n_female, n =n_total, p =0.5, correct =FALSE)
1-sample proportions test without continuity correction
data: n_female out of n_total, null probability 0.5
X-squared = 0.027027, df = 1, p-value = 0.8694
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.4421534 0.5489403
sample estimates:
p
0.4954955
Interpreting the output (what you should be able to say)
After running the code, you should be able to report:
The estimated proportion female (your point estimate)
The 95% CI for the proportion female
The p-value for the test of p = 0.5, and whether you would reject at a typical alpha level (e.g., 0.05)
Keep the interpretation strictly about the population proportion of females and whether the data are consistent with 0.5.
Student task: repeat the workflow with bison sex
In this task, you will apply the same workflow to the knz_bison dataset from the lterdatasampler package, using animal_sex.
The knz_bison dataset
This dataset contains records of American bison sampled at Konza Prairie. For this lab you will focus on:
animal_sex (a categorical variable)
Your tasks
Using bison with non-missing animal_sex:
Create a frequency table of animal_sex and report the sample size used.
Estimate the proportion female (and the proportion male, if present).
Compute a 95% CI for the proportion female using prop.test().
Conduct a hypothesis test of H0: p_female = 0.5 (two-sided) using prop.test().
Write 2–4 sentences summarizing your results in plain language, including:
the sample size for each sex
your estimate of the proportion female the 95% CI
the p-value and a clear conclusion about whether the data support p = 0.5
Wrap-up and submission
Before leaving lab:
Make sure your R script is saved in your Posit Cloud project and runs from top to bottom without errors.
Verify you have completed the student task (estimate, CI, hypothesis test, and answer questions on worksheet).
Show your worksheet, graph, and R script to an LA to get completion credit for the lab.